
Тест: угадай статью «Системного Блока» по картинке
Мы очень любим наших художников и дизайнеров инфографики. Иногда их работы говорят больше, чем слова. Мы собрали несколько примеров — попробуйте угадать, какие публикации они иллюстрируют.
Мы очень любим наших художников и дизайнеров инфографики. Иногда их работы говорят больше, чем слова. Мы собрали несколько примеров — попробуйте угадать, какие публикации они иллюстрируют.

В 2018 году мы запустили первое в русскоязычном пространстве медиа о пересечении цифровых технологий и гуманитарных наук, компьютерных алгоритмов и культуры, нейросетей и искусства. За семь лет мы заинтересовали более чем сотню тысяч читателей на разных платформах, собрали команду экспертов и авторов, живущих по всему миру, научились делать полезные гайды и большие дата-исследования и получили международную премию DH Awards. Рассказываем о наших любимых материалах последнего года, а также немного — о достижениях.

Японский язык — не просто средство общения, а визуальная система со своими законами. Он сочетает три разные письменности, требует особых шрифтов и умеет выражать эмоции одним символом. Как он работает в цифровом мире? Зачем японцам иероглиф травы вместо «лол»? Разберем, как японский язык адаптировался к интернету, шрифтам, мессенджерам и мемам.

В Национальном корпусе русского языка за последние годы появилось много новых инструментов. Один из них — это «Портрет слова», который не только содержит информацию о морфологических признаках и морфемах каждого слова, но и дает представление, например, о его семантических соседях. В статье мы покажем, как пользоваться этим и другими заметными нововведениями, и расскажем, какие технологии за ними стоят.

Как получить доступ к огромным массивам текстов из Telegram, чтобы изучать язык медиа, тренды или реакцию общества на события в мире? В этом помогут Telegram Desktop, Python и библиотека pyrogram. В гайде с кодом рассказываем о методе «цепной реакции» для поиска и скачивания целых групп связанных каналов. Превратите Telegram в ваш исследовательский полигон!

Языковые модели Google и OpenAI впервые получили золото в математической олимпиаде, вышли новые модели линейки Qwen3.

Многие школы и ученики до сих пор подвергаются кибератакам. При этом уроки кибербезопасности по-прежнему факультативны. Разбираемся, как превратить правила безопасности в привычку и почему игры эффективнее лекций и запретов.

Лаборатория Илона Маска выпустила обновление модели Grok, OpenAI представила ИИ-агента, стала доступна самая большая open-source LLM — что произошло в мире ИИ за последнее время.

Хотите сегодня работать с видом на море, а завтра — прямо из гор? 35 млн человек уже ответили да: они стали цифровыми кочевниками. Рассказываем, что скрывается за такой свободой без границ, как цифровое кочевничество меняет экономику и как живут те, чей «дом» определяется силой Wi-Fi, а не пропиской в паспорте.

Карфаген должен быть разрушен — но почему именно он? Возможно, дело вовсе не в злопамятности римлян, а в географии. Точнее, в транспортной сети, которую можно сегодня смоделировать с помощью ORBIS — цифрового проекта Стэнфорда. Методы сетевого анализа позволяют взглянуть на Римскую империю как на систему дорог, портов и городов, от которой в империи напрямую зависело все: торговля, власть, снабжение и, наконец, ее распад.

Кто-то, где-то, что-то, как-то, почему-то. Все мы часто используем неопределенные местоимения. Они спасают нас в минуту неуверенности и незнания. В 1997 году лингвист Мартин Хаспельмат описал, какие значения они могут выражать и какие закономерности есть в употреблении неопределенных местоимений. Рассказываем, чем эта классификация помогает ученым и как с помощью вычислительных методов можно показать стремление языков к оптимальности.

Слова, как и люди, любят компанию. У каждого есть свой круг «общения» — другие слова, которые часто встречаются рядом с ним в схожих контекстах. Однако этот круг меняется со временем. В XIX веке у слова могли быть одни «приятели», а в XXI — совершенно другие. С помощью Национального корпуса русского языка мы можем заглянуть в прошлое и увидеть, как трансформировались эти семантические окрестности. Сможете ли вы опознать слово, зная лишь его «компанию» из разных эпох? Пройдите наш тест и проверьте свою лингвистическую интуицию!

Почему ваши файлы на компьютерах и смартфонах до сих пор лежат в «папках»? Все началось с бухгалтеров XIX века и шкафов, похожих на небоскребы из бумаги. Эти офисные шкафы изменили работу с документами навсегда. А кое-что в них до сих пор используют даже спецагенты Малдер и Скалли 👀

Meta переманивает исследователей OpenAI, суд не нашел нарушений в обучении LLM от Anthropic на книгах, Apple планирует отдать разработку Siri одной из ключевых ИИ-компаний — что произошло в мире ИИ за последнее время.

ИИ уже пришел в университеты — но что он там делает? Помогает думать или разрушает мотивацию? Усиливает мышление или заставляет мозг деградировать? В этом материале — пять сценариев того, как ИИ может изменить высшее образование. Какой из них кажется вам самым реальным?

Готовы почувствовать себя Шерлоком Холмсом? Проверьте свои знания о криминалистической биоинформатике: как с помощью ДНК, пыли, грибов и микробиомов можно раскрыть преступления.

Как «разложить» все книги мира на одной гигантской полке? 📚 Оказывается, для этого достаточно внимательно посмотреть на коды ISBN. Рассказываем, как превратить набор цифр в книжную вселенную в одном визуальном пространстве, по которому можно гулять.

Видеогенерация в Midjourney, инвестиции Meta в компанию по разметке данных, новая модель Mistral — что нового в мире ИИ произошло за последнее время.

Что происходит, когда методы открытой науки и алгоритмического анализа встречаются с тысячелетним китайским культурным наследием? Исследовательская группа из Болоньи отправилась в Пекин, чтобы узнать, как Digital Humanities развиваются в крупнейшем университете Китая. Мария Левченко, участница группы, рассказывает об итогах этой поездки.

Папки, картотеки, скоросшиватели — только на первый взгляд кажется, что это скучные атрибуты офиса. За простыми на вид способами организации документов стоит целая история о том, как люди учились хранить информацию. Исследователь истории науки и техники в Центре непрерывного образования факультета компьютерных наук НИУ ВШЭ Антон Басов рассказывает о значении бумаги для развития капитализма и IT, а также о противостоянии горизонтального и вертикального хранения.

Что будет, если заменить школьные учебники планшетами? С одной стороны, информация по одному запросу — мечта любого ученика. С другой — уведомления, гиперссылки и котики в TikTok, которые так и манят отвлечься. Цифровое чтение становится все более распространенным, но умеем ли мы правильно читать с экранов? В этой статье разберем, как эти технологии меняют образование, что об этом говорит наука и как учителям правильно выстраивать обучение в этих условиях.

Готовы ли вы совершить захватывающее путешествие в мир древности, используя современные технологии? Палеогенетика и биоинформатика воссоздают историю наших предков через анализ их ДНК. Пройдите наш тест и проверьте свои знания о том, как наука помогает расшифровывать загадки прошлого!

Можно ли с помощью нейросетей находить скрытые цитаты, аллюзии и сближения в художественных текстах? Конечно! Что будет, если объединить силу LLM с экспертизой литературоведов, — читайте в материале математика, специалиста по Computer Science и одновременно литературоведа Евгения Обухова.

Все мы читали сказки, где предметы действуют, как люди: печка помогает скрыться от Бабы-яги, дубинка сама решает, кого ей побить, а ковер летит куда хочет. Сказки братьев Гримм — не исключение. Филологи из Дармштадта решили разобраться, как работает эта литературная магия, и обучили компьютер отличать живое от неживого в текстах. Рассказываем, как цифровые методы помогают исследовать одушевленность в волшебных сказках.

DeepSeek R1 обновился, OpenAI строит суперкомпьютер в ОАЭ, в Telegram появятся ИИ-функции на основе Grok — что произошло в мире ИИ за последнее время.

Драконы, духи и герои древних легенд теперь не бродят по туманным мирам — они появляются на картах. Современные базы данных и GIS-технологии позволяют визуализировать фольклорные и мифологические сюжеты. Рассказываем о цифровых картах, которые помогут вам проследить путь Одиссея и найти все проклятые места в Ирландии.

Хотите узнать, какие страны воевали больше всего? Сколько было войн и где происходили ключевые битвы? Рассказываем о Всемирной базе данных исторических сражений, которая содержит информацию о более чем 8000 военных конфликтах — от древности до наших дней.

Как современные технологии меняют подход к изучению древних надписей? Какие методы используют исследователи для сохранения исторического наследия? Пройдите наш тест и выясните, насколько хорошо вы разбираетесь в цифровой эпиграфике.

Компания Google представила новые AI-продукты, Anthropic выпустила свежие версии своих моделей, бывший главный дизайнер Apple разработает новое устройство для OpenAI — что произошло в мире ИИ за последнее время.

Каждый, кто говорит по-русски, знает, что роль играют, условия выдвигают, а глаза бывают карими, но не коричневыми. Такие устойчивые словосочетания называются коллокациями, и существовать без них не может ни один язык. Мы уже рассказывали о том, как коллокации помогают гуманитариям, а теперь сделали тест, который поможет вам разобраться в этой теме. Готовы проверить свои знания?

Как работает поиск изображений по текстовым описаниям? Как это связано с генерацией изображений? Как языковые модели «понимают» не только текст, но и изображения и аудио? Рассказываем, как нейросети работают с разными типами данных одновременно.

Искусственный интеллект повсюду: заменяет врачей, ищет нефть, а инженеры разрабатывают специальные чипы для машинного разума. Звучит как заголовки из 2025 года? На самом деле — это 1980-е. Тогда мир потрясли экспертные системы — предки современного ИИ. Почему они не покорили мир и какие уроки их взлета и падения актуальны сегодня? Разбираемся в самой поучительной истории технологического бума.

Аллюзиями в литературе называют отсылки на другие художественные произведения, известные высказывания и реальные исторические события, которые могут быть хорошо известны читателю. Аллюзии создают межтекстовый диалог, служат данью уважения классикам жанра и делают повествование более многоуровневым. Но как быть с текстами на латыни, где для понимания аллюзий надо понимать контекст культуры и истории Древнего Рима? Рассказываем о проекте Tesserae, который помогает находить аллюзии и цитаты в древнеримской литературе.

Подумайте о своем любимом книжном персонаже. Как он выглядит? что думает? как взаимодействует с другими? Мы можем описать образ героя, перечислив эти и другие черты, или проанализировать его, используя другие внутритекстовые данные. Рассказываем, как с этой задачей справятся большие языковые модели.

Как называли алоэ или шиповник травники XIII века или аптекари времен Петра Великого? Ученые из Европейского университета в Санкт-Петербурге создали базу данных PhytoLex, в которую внесли обозначения растений в ботанических, медицинских и этнографических источниках XI–XVIII веков. Подробно об этом проекте мы рассказали здесь. Предлагаем вам попробовать себя в роли историка ботаники: сможете ли вы угадать современные названия растений по их «паспортным данным» из прошлого?

Координатные оси, кластеризация, столбчатая диаграмма, хронологическая прямая… Нет, мы не на уроке математики и не пытаемся постичь Excel. Мы всего лишь изучаем музейную коллекцию работ художников эпохи Возрождения. Эта статья о том, как и зачем в музеях визуализируют данные (и откуда они там вообще).

В новой подборке мы рассказываем об инструментах, которые используют востоковеды для изучения японского языка и цифровых исследований японских текстов: от онлайн-словарей до продвинутых методов стилометрии.

Google открыла доступ к ИИ-поиску американским пользователям, вышло третье поколение языковой модели Qwen, OpenAI после жалоб пользователей вернула менее подобострастную версию GPT — что произошло в мире ИИ за последнее время.

Ухемоль, лоландер, рудада — спорим, вы не слышали таких слов? Мы тоже, пока не начали составлять этноботаническую базу данных PhytoLex. Рассказываем, для чего используется эта база данных и что можно узнать с ее помощью: от этимологии слова до его эволюции сквозь века.

Китайское письмо, появившееся более трех тысяч лет назад, — одна из древнейших письменностей в мире. Однако не менее интересна история китайских цифровых гарнитур и шрифтов. Вековые традиции каллиграфии, региональные особенности написания иероглифов и реформы Мао Цзедуна — все это повлияло на становление оригинальной классификации стилей шрифтов, в чем-то опирающейся на европейскую, а в чем-то уникальной.

ЕГЭ — нервное событие, а подготовка к экзаменам — долгая и сложная. На помощь ученикам и учителям приходят сервисы на базе искусственного интеллекта. Сравниваем «Сочинитель», «Яндекс Учебник» и Skysmart AI с популярными нейросетями. И технологично готовимся к итоговому сочинению, ЕГЭ по информатике и английскому языку.

Пуш-уведомления в сфере образования: друг или враг? Мотивируют ли студентов всплывающие напоминания на повторение материала? В этой статье мы расскажем о неоднозначных результатах двух исследований.

DeepSeek — новая китайская нейросеть, вызвавшая фурор как среди простых пользователей, так и специалистов. Некоторые даже окрестили ее «убийцей ChatGPT». В новом обзоре мы подробно расскажем о функционале этой нашумевшей нейросети, поделимся рекомендациями по ее использованию и ответим на самые распространенные вопросы о возможностях DeepSeek.

OpenAI представила сразу несколько обновленных моделей (GPT-4.1, o3 и o4-mini), вышел детальный прогноз развития ИИ до 2027 года — что произошло в мире ИИ за последнее время.

Коллокации — это словосочетания, в которых слова часто встречаются рядом. Рассказываем, как устроены коллокации и какие есть способы их выявлять. А также изучим с помощью коллокаций в НКРЯ, что представлял собой антисемитизм в Российской империи второй половины XIX века.
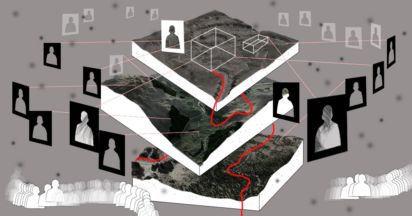
Исследование мест массовых убийств позволяет высветить обстоятельства и корни преступление против человечности, а также делает нас свидетелями прошлого. Современные технологии не только позволяют по-новому взглянуть на то, что хорошо известно, но и способны пролить свет на то, что долгие десятилетия было сокрыто — в том числе, глубоко под землей. В новом большом материале рассказываем, как цифровые методы в археологии помогают ученым исследовать концентрационные лагеря, газовые камеры и лагерную инфраструктуру.
Политизированные споры вокруг разграничения русского, украинского и белорусского языков, междисциплинарные исследования нейролингвистов, аудиозаписи Александра Блока. В фокусе новой подборки интервью «Системного Блока» — лингвистика. Наши собеседники рассказали о языковой смерти, компьютерных методах для церковных текстов, дистрибутивной семантике и о лингвистических экспедициях.

Современный педагог сталкивается с рядом вопросов: как учитывать весь объем информации? какие технологии использовать? как учесть индивидуальные особенности ученика? Доказательное образование — это подход, при котором педагогические практики основываются на надежных научных исследованиях. Перед тем как внедрять новый метод, его тестируют, как лекарства в медицине, где экспериментальные исследования более распространены. В педагогике же проводить тесты сложнее из-за этических и организационных ограничений. Тем не менее, доказательное образование активно развивается.

Геоглифы Наски известны людям с XVI века — о них упоминали конкистадоры, которые проходили через пустыню. Тем не менее научное изучение геоглифов началось сравнительно недавно, чуть менее 100 лет назад, и стало возможным благодаря новым технологиям. С тех пор было открыто более 430 фигуративных, то есть составляющих изображение, геоглифов, а также множество линий, пересекающих пустыню.

Выдающийся филолог-структуралист Ролан Барт полагал, что каждый текст — это интертекст, то есть в каждом тексте присутствуют в более или менее узнаваемых формах тексты предшествующих и настоящих культур. Рассказываем о свежем цифровом исследовании интертекстуальности в корпусе французских текстов и пробуем разобраться, как функционируют канон и жанр в литературном процессе.

Вышло новое поколение Llama, Gemini 2.5 Pro стала лучшей LLM, а GPT сильно улучшила генерацию изображений — что произошло в мире ИИ за последнее время.

Вы уверены, что, если подойти к принтеру с южной стороны, он не будет печатать? Ваши друзья заботятся о своей карме в цифровом пространстве, а коллеги в очередной раз просят распространить цепочку «писем счастья»? Разбираемся, какие суеверия возникают по поводу технологий и как их природу объясняет наука.

Интернет и программирование: как много в этом звуке для сердца русского слилось! Читайте в нашей подборке, как писатели в начале XX века предсказали интернет, как в Советском Союзе пытались создать суверенную электронную сеть и почему советские и русские программисты стали цениться во всем мире.

По запросу «микрообучение» (или microlearning) вы найдете тысячи однотипных страниц, демонстрирующих кривую забывания Эббингауза и непременно продающих свои курсы. «Учитесь по 15 минут в день и запоминайте лучше!», «Поглощайте знания небольшими порциями, как этого требует современный темп жизни!», «Наши курсы — это будущее образования!». Разбираемся, насколько оправданы эти заявления, и рассказываем, что на самом деле представляет собой микрообучение.

Средневековые студенты часто перемещались из одного университета в другой, чтобы получить всестороннее образование и ученую степень. Все это, наряду с их происхождением, статусом и другими характеристиками, тщательно документировалось. В результате сегодня ученые могут создавать базы данных выпускников и преподавателей прошлого. Об одной из них — Repertorium Academicum Germanicum — рассказываем в нашем новом материале.

OpenAI выступила за ужесточение доступа к чипам, экспортируемым из США, Google и Mistral обновили свои открытые модели — что произошло в мире ИИ за последнее время.

Aozora Bunko — это цифровая библиотека, где собраны произведения японской классической литературы, которые находятся в открытом доступе. «Системный Блокъ» рассказывает, как устроена библиотека, какие правовые нормы приняты в Японии и о том, как автоматически собрать свой корпус из материалов «Аодзора-бунко».

Могут ли Объединенные Арабские Эмираты конкурировать с мировыми державами за первенство в сфере искусственного интеллекта? Рассказываем, что ОАЭ делают (а также НЕ делают) для того, чтобы к 2031 году стать лидером в области ИИ, и как страна реагирует на риски, связанные с быстрым развитием генеративного ИИ.

Могут ли новые технологии помочь прочесть нечитаемую древнюю надпись на камне? Как трехмерные модели старинных надгробий, крестов, камней и эпиграфических табличек позволяют не только сохранить эти памятники в цифровой форме, но и добыть новое знание о прошлом? Знакомимся с проектом «Свод русских надписей», проблемами работы эпиграфистов и тем, как решать насущные проблемы в этом направлении.
Благодарим за помощь в написании статьи сотрудника проекта «Свод русских надписей» Анну Зиганшину.

Можно ли применять алгоритмы определения авторства к текстам древних исландских саг? Какие гипотезы о создателях этих текстов помогает подтвердить метод дельты, который ранее применяли для поиск поддельных стихов XIX века и раскрытия псевдонима Джоан Роулинг? Рассказываем про исследование исландского лингвиста Хёйка Торгейрссона.