
Проблемы больших данных
Для тренировки LLM обычно используются огромные корпуса наподобие Common Crawl, Colossal Clean Crawled Corpus (C4) и The Pile, которые представляют собой коллекции веб-страниц. Однако у такого подхода есть проблемы:
- доминирование английского языка, поскольку большая часть материалов написана именно на нем;
- низкая представленность других языков соответственно;
- содержание веб-страниц категоризуется (напр., на статьи arXiv или PubMed, страницы Википедии, тексты социальных сетей), но выделенные группы могут быть слишком широкими и не отражать важных подробностей о данных;
- веб-страницы могут содержать краудсорсинговые и синтезированные (сгенерированные LLM) данные, которые нуждаются в дополнительной постобработке — чистке от ошибок, галлюцинаций, предвзятости.
Сейчас исследователи стремятся к обеспечению качества и прозрачности данных. Например, Шарль де Дампьер, Николя Баумард и Андрей Могутов [1] создали библиотеку BunkaTopics, которая позволяет изучать тематику обучающих датасетов и проверять их на смещение в сторону того или иного фрейма.
Тематическое моделирование текстов датасета
Тематическое моделирование (ТМ) — это направление NLP, исследующее тематическую составляющую текстов. Системный Блокъ уже писал о том, как провести ТМ самостоятельно, здесь и тут.
В BunkaTopics встроен инструмент, позволяющий провести ТМ текстов, которые содержатся в датасете. Он работает так:
- векторизует тексты датасета,
- уменьшает размерности векторов,
- смотрит на их сходство и кластеризует похожие слова,
- визуализирует кластеры (топики) в виде 2D карты, рельеф которой представляют тексты датасета.
Выделенные топики называются с помощью самых специфичных для них существительных. Пользователь может переименовать их на свое усмотрение или использовать LLM для интерпретации. Например, на Рис. 1 виден кластер Objects | Strings | Functions |Ways | Web, позже переименованный в Programming Concepts с помощью LLM.

Рис. 1. Пример выдачи ТМ без переименования топиков (используются самые специфичные существительные). Источник: [1]
В интерфейсе BunkaTopics (доступен в бета-версии) справа от тематической карты располагаются самые подходящие под топик документы, ранжированные по релевантности. Например, на Рис. 2 красной линией выделена тема Creative Expression, и справа можно увидеть, какой процент карты она занимает, а также относящиеся к ней документы. Эта карта построена по данным Prompt-Collective Dataset — набора промптов, составленных людьми и LLM. Судя по визуализации, тематика промптов затрагивает в основном математику, программирование, работу с данными, экологию, приготовление пищи, здоровье и уже упомянутое творчество.
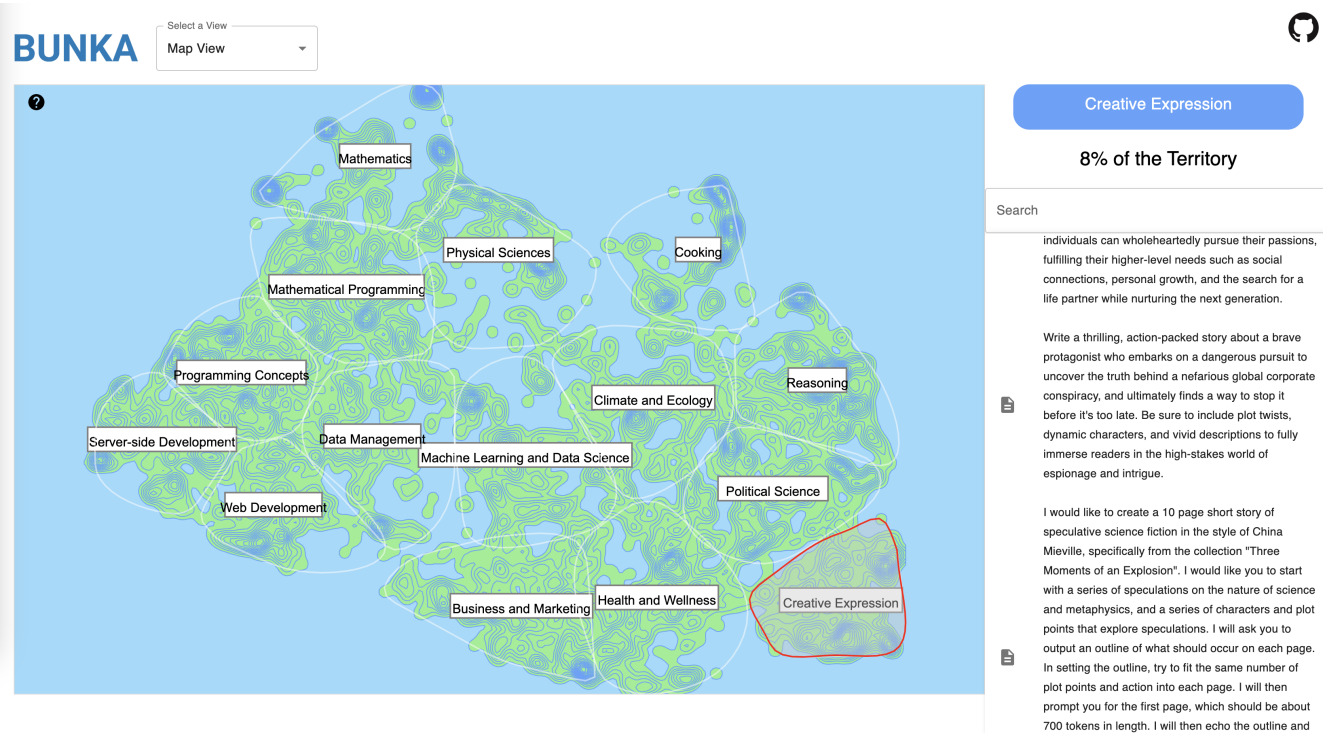
Рис. 2. Интерфейс тематического моделирования в Bunkatopics. Авторы применили LLM для названия топиков. Справа показаны самые специфичные для темы Creative Expression тексты из Prompt-Collective датасета. Источник: [1]
Технические детали работы ТМ в BunkaTopics (используемые пакеты, модели, метрики) можно найти в статье [1].
Тематическое моделирование для очистки данных
Direct Preference Optimization (DPO) — техника, которая позволяет обучить языковую модель выдавать более предпочтительные ответы с точки зрения содержания, полезности, стиля и т. д. Датасет ChatML DPO Pairs содержит запросы, а также более подходящие и менее подходящие ответы на них (в датасете они называются «принятые» и «отвергнутые» соответственно). Чтобы понять, какой ответ больше понравится пользователю, важно видеть четкие различия между вариантами. Создатели BunkaTopics предлагают использовать ТМ для этой задачи.
На Рис. 1 видно, что тематические кластеры пересекаются. BunkaTopics позволяет чистить данные от пересечений. Если два и более специфичных существительных совпадают в двух и более топиках, последние можно удалить.Для тестирования инструмента исследователи провели эксперимент. Они выделили 30 топиков в принятых и отвергнутых ответах, а затем посмотрели, сколько из них пересекаются. Из 30 топиков 17 имели пересечения. Исследователи взяли промпты, которые относились к 13 топикам, встречающимся только в «хороших» ответах, и использовали их для дообучения модели teknium/OpenHermes-2.5-Mistral-7B. Итог назвали Topic Neural Hermes. Результаты работы модели оценили на известных бенчмарках* (рис. 3) и сравнили с базовой моделью, а также версией, обученной на неочищенном ChatML DPO датасете (mlabonne/NeuralHermes-2.5-Mistral-7B). Topic Neural Hermes превзошла базовую модель по всем тестам (Рис. 3). По сравнению с NeuralHermes она показала лучшие результаты везде, кроме WinoGrande (тот же результат) и GSM8K (NeuralHermes справилась на 7 единиц лучше).
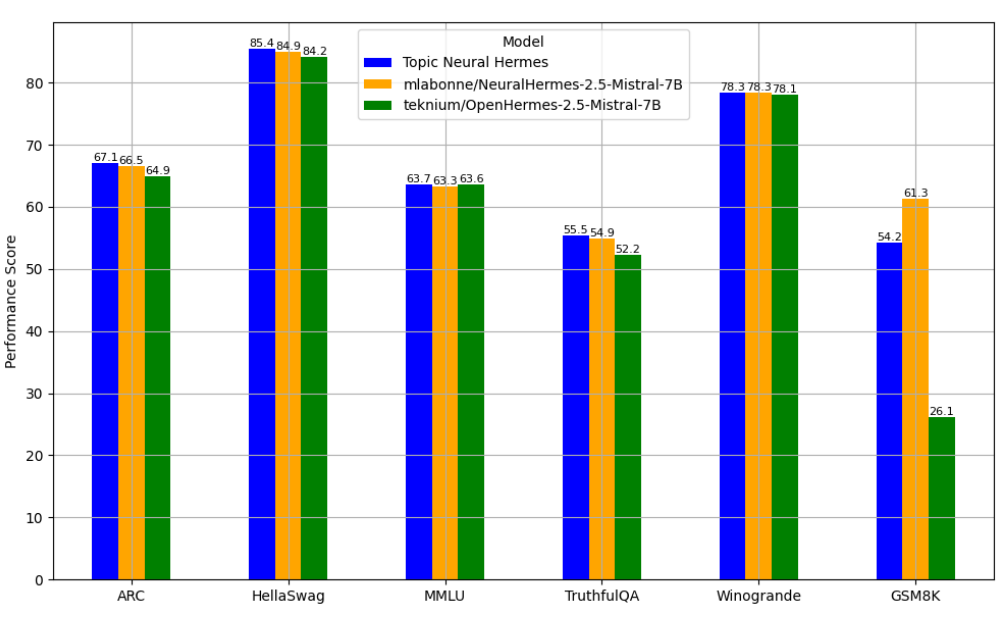
Рис. 3. Результат оценки дообученных и базовой моделей на бенчмарках. Источник: [1]
Таким образом, исследователям удалось снизить количество обучающих данных до 1/6 оригинального датасета и достичь при этом сопоставимых или лучших результатов.
* Бенчмарк — набор данных, тестов/заданий и метрик для оценки работы LLM.
Фреймовый анализ для поиска смещения в данных
Если не вдаваться в подробности, фрейм в лингвистике — это когнитивная рамка ситуации, помогающая интерпретировать слова высказывания в ее контексте. Например, в отзыве о ресторане слова дорогой и дешевый означают стоимость не самого заведения, а блюд, сервиса и других составляющих в нем.
Авторы BunkaTopics предлагают использовать концепцию фреймов для поиска смещения в данных. На Рис. 4 виден результат анализа уже упомянутого Prompt-Collective датасета на смещение в сторону будущего/прошлого и работы/отдыха. Исследователи выбрали фреймы произвольно, в документации к библиотеке можно найти другие примеры. Принадлежность текстов датасета (= входящих в него промптов) тому или иному фрейму проверялась по косиносному сходству с предложениями: this is about the future («это о будущем»)/this is about the past («это о прошлом») и this is about the work («это о работе»)/ this is about the leisure («это об отдыхе»).
В результате выяснили, что в Prompt-Collective датасете большая часть текстов (69.2%) относится к будущему, связанному с работой. Соответственно, в нем присутствует смещение в данную сторону. Точки на Рис. 4 представляют промпты датасета, а существительные выделены с помощью модуля тематического моделирования Bunka для лучшего понимания изображенного.

Рис. 4. Анализ текстов Prompt-Collective датасета на смещение в сторону прошлого/будущего и работы/отдыха. Источник: [1]
Где искать код для исследования данных?
BunkaTopics — библиотека для изучения данных. С ее помощью можно исследовать темы, затронутые в текстах, и узнавать, есть ли смещение в сторону того или иного фрейма. Она будет полезна для исследования любых текстовых датасетов, не только тех, что используются для обучения LLM. Авторы проекта написали четыре тетрадки с кодом, демонстрирующие возможности инструмента и обучающие его использованию. Найти их можно в репозитории Bunka. Также советуем почитать документацию.
Источник: De Dampierre C., Mogoutov A., Baumard N. Towards Transparency: Exploring LLM Trainings Datasets through Visual Topic Modeling and Semantic Frame. URL: https://arxiv.org/abs/2406.06574 (дата обращения: 25.08.25).
Что еще почитать
- Zhu W., Hessel J., Awadalla A., Gadre S., Dodge J., Fang A., Yu You., Schmidt L., Wang W., Choi Ye. Multimodal C4: An Open, Billion-Scale Corpus of Images Interleaved with Text. URL: http://arxiv.org/abs/2304.06939 (дата обращения: 25.08.25).
- Gao L., Biderman S., Black S., Golding L., Hoppe T., Foster Ch., Phang J., He H., Thite A., Nabeshima N., Presser Sh., Leahy C. The Pile: An 800GB Dataset of Diverse Text for Language Modeling. URL: http://arxiv.org/abs/2101.00027 (дата обращения: 25.08.25).

